
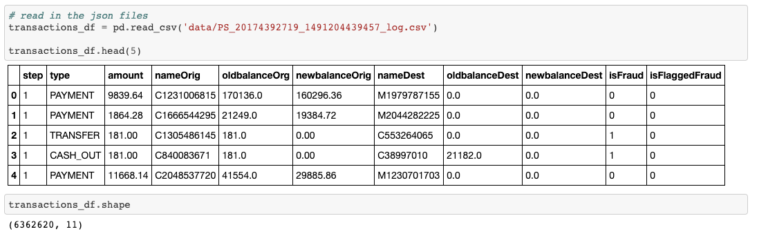
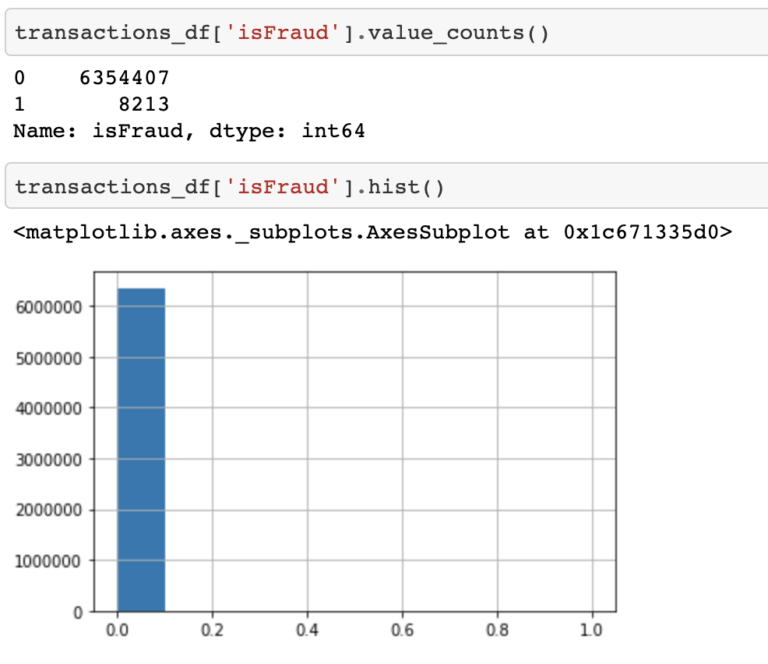

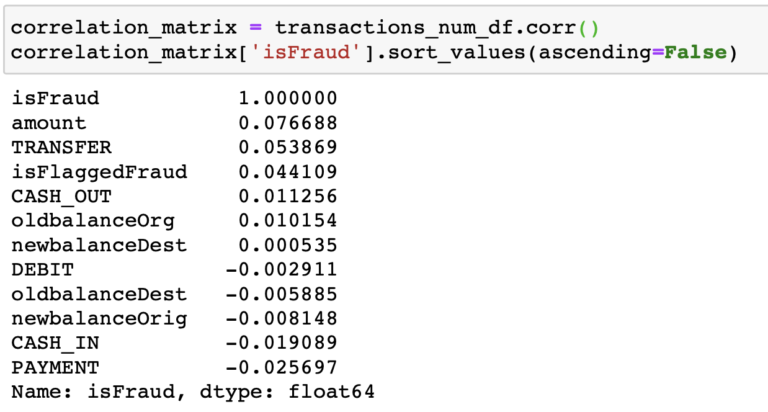
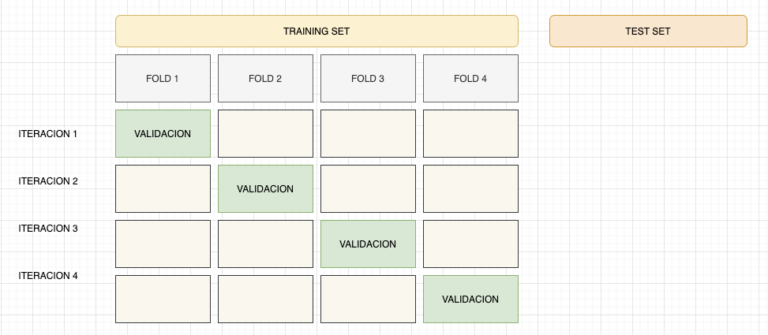


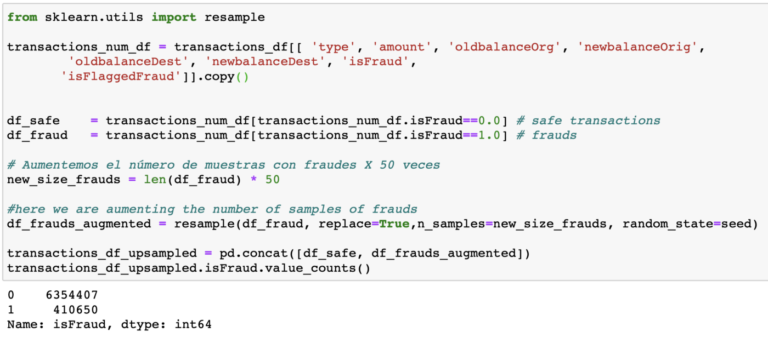
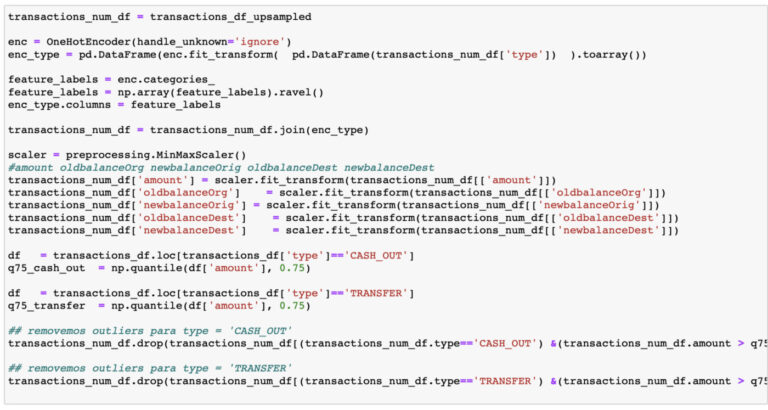
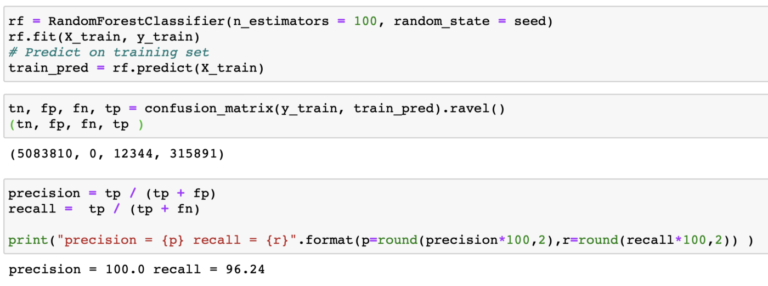

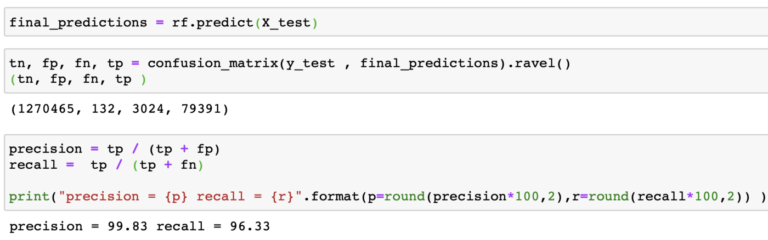
Es este modelo perfecto? realmente no lo creo, podemos decir que es bueno para el set de datos actual y que es un buen comienzo para pensar en un set de datos más complejo y rico que pueda representar con mas detalle la realidad de las transacciones financieras.
Si me encargaran la tarea de crear un modelo nivel productivo de predicción de fraudes financieros, comenzaría por tener set de datos mucho mas grande, y que incluyera más features, las cuales podrían ser:
dayOfWeekTx
hourOfDayTx
monthTx
isBlackListedIp
isFrequentDestAccount
isFrequentMerchant
isFrequentLocation
invalidLocationInTimeFrame
channelWeb
channelATM
channelMobile
isAnAverageTxAmount
isLookABurstOfTxs
Todas las features anteriores pueden ser calculadas sin mayor problema justo al momento de evaluar la posibilidad de fraude de una transacción en curso. Solo es cuestión de crear los pipelines de datos necesarios para capturar las estadísticas de cada cliente.
Si te gustó este post agradecería que lo compartieras en tus redes sociales 🙂 gracias!!
El código de este proyecto se encuentra en
https://github.com/ortizcarlos/fraud_detection/blob/master/Financial%20fraud%20detection.ipynb



