
AI in Colombian container terminals, more than a buzzword
After writing a series of articles on how to apply IA to recruiting, I decided it was time to take a break and change the topic of my articles (at least temporarily).
This article is the continuation of a series of posts covering applying AI and semantic search to tech recruitment. You can read them here:
Here I’ll start delving into the details of the system architecture of a sourcing platform empowered by AI. I hope this architecture can be used by companies as a reference to build up or re-structure their sourcing or AMS (Applicant Management System) platform.
The following are the primary functionalities of the platform:
So, our platform has at least nine features, each one with its complexity. Also, we need to define the base architecture that will glue those functionalities together.
As that’s a lot of information to cover in a single article, I’ll focus in this one solely on the system design and on the following features:
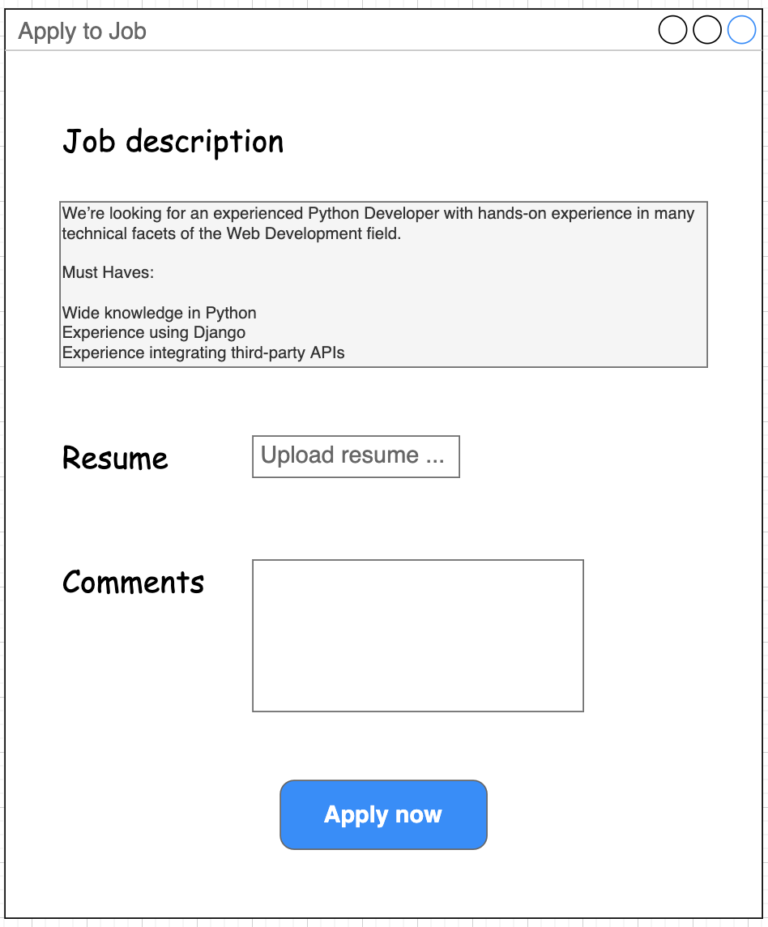
The following is a simple mock-up (UI design is not one of my strengths 🙂 ) of the “Apply to job“ form. Almost all the features listed above are triggered just after the candidate presses the “Apply now” button.
The toolbox I propose in this article would allow:
– Car repair shops and insurance agents to automate their damage inspection process.
– Car washes can quickly generate an inspection of the cars they receive thus avoiding possible problems with car owners for surprise dents.
Before delving into the details of the system design, we need to define some metrics about the platform, so we can use that information to design a sound architecture:
The previous information can help us size some of the following key elements:
Now, let’s make some architectural decisions based on the fact we want to design a performant, traceable, secure, and scalable platform:
The following is the list of stacks, frameworks, and tools we are using to build the solution:
In other words, CLIP can determine, given an image and a set of labels, which of that labels best describes the input image.
I encourage you to read the complete description of this amazing model here; I think it is good to know why CLIP is a game-changer in the visual classification field and what was the approach that OpenAI used to build it.
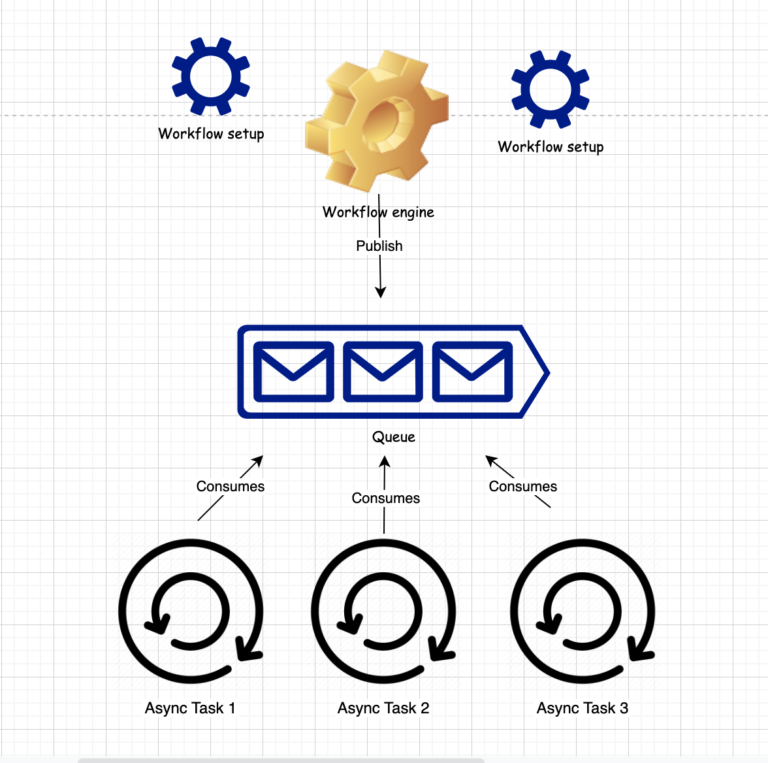
As we stated before, we want a performant and scalable platform. So using async processors or microservices orchestrated by a workflow engine is a good architectural decision.
Now is the time to start designing and developing the async task that will implement the following features:
1 — Extracting key information from the applicant’s resume. Including (programming languages, technologies, frameworks, and education). That can be used for keyphrase searches and candidate filtering. Also, label the candidate´s profile in the following categories: management, development, or QA.
2 — Ranking candidate’s resume to a job post.
Task 1 — Extracting key information from the applicant’s resume.
The command to trigger this task can be a JSON string as the following:
{
"resume_path" : "path_to_resume_in_the_blog_storage",
"job_post_id" : "e2c89a30-4a87-11ed-b878-0242ac120002",
"candidate_id" : "f3ff2102-4a87-11ed-b878-0242ac120002",
"organization_id" : "266edfc4-4a88-11ed-b878-0242ac120002",
"workflow_id" : "108309444",
"task-code" : "rs001"
}
We can expect the output of this task to be something like this:
{
"candidate_id" : "f3ff2102-4a87-11ed-b878-0242ac120002",
"workflow_id" : "108309444",
"profile_details" : {
"profile_categories": ['Developer'],
"technical_skills" : ['Ethereum','Solidity', 'Golang', 'Node.js', 'Angular.js', 'React'],
"education" : "I have M.Tech in Computer Engineering from Jaipur, Rajasthan Malaviya National Institute Of Technology Jaipur.",
"relevance_score" : "0.734"
}
}
We have at least two alternatives to implementing the current functionality.
The first alternative is based on GPT-3. Here we extract the key information by sending a prompt with the candidate`s resume as context and some relevant questions and commands. Next, you can see an example of such a prompt:
Skills Strong CS fundamentals and problem solving Ethereum, Smart Contracts, Solidity skills Golang, Node, Angular, React Culturally fit for startup environment MongoDB, PostGresql, MySql Enthusiastic to learn new technologies AWS, Docker, Microservices Blockchain, Protocol, ConsensusEducation Details
January 2014 M.Tech Computer Engineering Jaipur, Rajasthan Malaviya National Institute Of Technology JaipurBlockchain Engineer - XINFIN Orgnization
Skill Details
MONGODB- Exprience - 16 months
CONTRACTS- Exprience - 12 months
MYSQL- Exprience - 9 months
AWS- Exprience - 6 months
PROBLEM SOLVING- Exprience - 6 monthsCompany Details
company - XINFIN Orgnization
description - Xinfin is a global open source Hybrid Blockchain protocol.
Rolled out multiple blockchain based pilot projects on different use cases for various clients. Eg.
Tradefinex (Supply chain Management), Land Registry (Govt of MH), inFactor (Invoice Factoring)
Build a secure and scalable hosted wallet based on ERC 20 standards for XINFIN Network.
Working on production level blockchain use cases.
Technology: Ethereum Blockchain, Solidity, Smart Contracts, DAPPs, Nodejs
company - ORO WealthAnswer the following questions:1 - List the programming languages and frameworks you have worked with.
2 - What did you study at school?
3 - List the databases you have worked with.
4 - Classify the candidate between the following categories: Developer, QA, DevOps, or Manager.
Answers:
Then we just have to parse the GPT-3 answer to provide the expected JSON response.
Answers:1
- I have worked with Ethereum, Solidity, MongoDB, AWS, Docker, and Microservices.
2 - I studied M.Tech Computer Engineering at Jaipur, Rajasthan Malaviya National Institute Of Technology Jaipur.
3 - I have worked with Ethereum, MongoDB, MySQL, and PostgreSQL.
4 - I would classify the candidate as a Developer.
Having the answer list from GTP-3, extracting the candidate category label is extremely easy; we just have to parse the fourth answer. In this case:
4 – I would classify the candidate as a Developer.
The second alternative to implementing this task is to train and use a custom Named Entity Recognition (NER) model based on Hugging Face Transformers to label programming languages, frameworks, and databases (more on that in another post).
Task 2 — Calculate the relevance of the candidate’s resume to a job post.
The idea here is to calculate how relevant is the candidate´s resume to the job post he is applying to.
We are using the SentenceTransformer library to extract the embeddings of both the job post and the candidate’s resume. Then we calculate the cosine similarity of both vector embeddings to see how similar they are.
from sentence_transformers import SentenceTransformer, utilmodel = SentenceTransformer('sentence-transformers/multi-qa-mpnet-base-dot-v1')
#Resume and job post are encoded by calling model.encode()
jobpost_emb = model.encode(jobpost)
resume_emb = model.encode(resume)
score = util.cos_sim(jobpost_emb, resume_emb)
We have reached the end of our adventure of designing the architecture of a sourcing platform assisted by AI. This is the first of a series of articles I plan to write to describe most of the technical challenges in creating a viable solution.
I hope this article has been helpful. Please add your comments if you have any questions or ideas about some other features you want to see on the platform.
Thanks for reading!
Stay tuned for more content about GPT-3, NLP, System design, and AI in general. I’m the CTO of an Engineering services company called Klever, you can visit our page and follow us on LinkedIn too.
After writing a series of articles on how to apply IA to recruiting, I decided it was time to take a break and change the topic of my articles (at least temporarily).
After writing a series of articles on how to apply IA to recruiting, I decided it was time to take a break and change the topic of my articles (at least temporarily).