Have you ever wanted a sourcing platform where you could start a recruitment workflow with this text:
“Startup is looking for a founder engineer with experience in Ethereum and smart contracts. Experience in frontEnd development with Angular is also desired.”
And then that system returns you a list of candidates as:
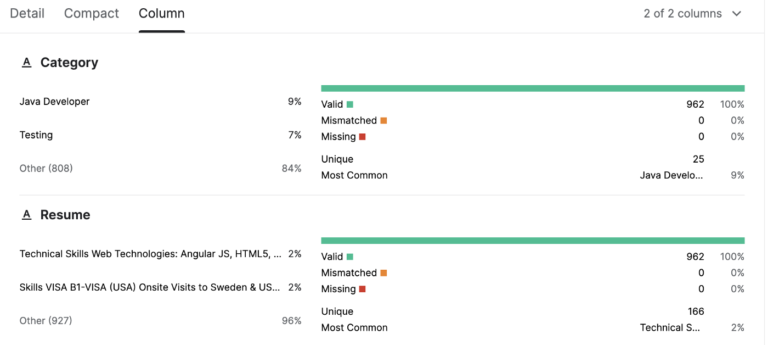
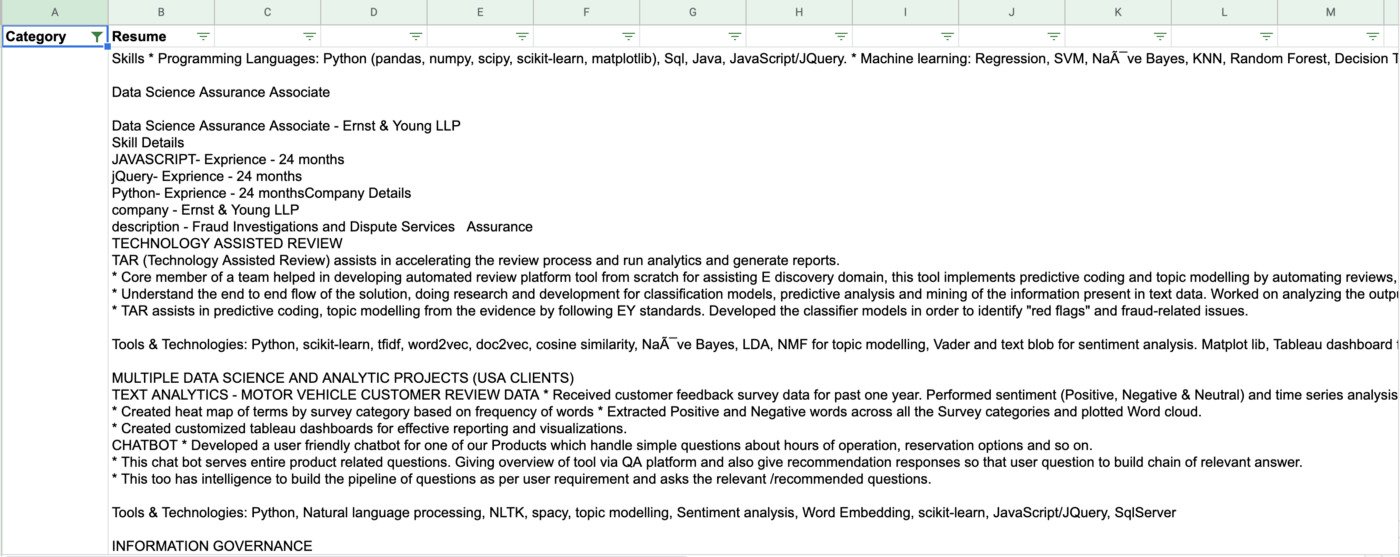
CATEGORY: Blockchain
RESUME: Skills Strong CS fundamentals and problem solving Ethereum, Smart Contracts, Solidity skills Golang,…
— —
CATEGORY: Blockchain
RESUME: SKILLS Bitcoin, Ethereum Solidity Hyperledger, Beginner Go, Beginner R3 Corda, Beginner Tendermint, Nodejs, C Programming …
— —
And for the highest-ranked candidate, the system would automatically ask and provide the following answers:
1 — What are your main technical skills?
2 — What was your major at school?
3 — Please list all the SQL databases you have worked with.
4 — Can you List all your work experience?
Answers:
1 — My main technical skills are CS fundamentals and problem solving, Ethereum, Smart Contracts, Solidity skills, Golang, Node, Angular, React.
2 — I have M.Tech in Computer Engineering from Jaipur, Rajasthan Malaviya National Institute Of Technology Jaipur.
3 — I have worked with MongoDB, PostgreSQL, MySql.
4 — I have worked with Ethereum, Smart Contracts, Solidity, Golang, Node, Angular, React, CakePHP (PHP Framework), JQuery, MySql.
Looks interesting, right? In this post, I will show you a quick approach to building a recruitment platform based on AI that implements these nice features described above. However, here I’m not going to dive deeply into the theory behind the tools and concepts used here; I’m sure you can follow the dots and go into further conceptual details yourself.
The following are the concepts, tools, and libraries that I used to build this prototype:
1 — Semantic search.
2 — Embeddings.
2 — Facebook Faiss.
3 — Hugginface’s Transformers.
4 — Huggingface’s datasets.
5 — Openai’s GPT-3.
6 — A resume dataset hosted in Kaggle.
This article is the continuation of an initial post on Resume Analysis with GTP-3 that I published before.